아이템 간의 유사도를 계산 == 비슷한 아이템 찾기
(사용자 기반은 나와 비슷한 사용자 (피어그룹) 찾기였음.)
[특징]
- 사용자 기반과 동일하게 평균 중심 변환(Mean Centering)을 함. (row가 0이 되도록)
- 피어슨 상관계수보다 성능이 좋은 "조정된 코사인 유사도" 사용

1. r_ut 평점 예측
u번째 사람이 예측한 타겟 아이템 t의 평점을 구하는 과정.
- Q_t(u): 아이템 t와 유사한 top-k 아이템 그룹
- 사용자 기반에서 제안된 변형 방법 동일하게 적용 가능

[예시 목표]
사용자 3이 아이템 1번, 6번에 줄 평점을 예측
1. 아이템 1과 6의 유사 아이템 그룹 찾기

- 노란 박스는 기준 아이템, 분홍 박스는 비교 아이템
- 1, 3번에 모두 평점을 매긴 사용자 1,4,5의 평점을 이용.
아이템 1과 3의 유사도 계산 과정은 아래와 같음.

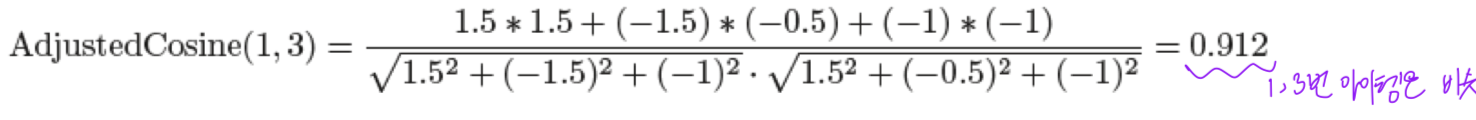
2. Top-K 설정

k=2(유사도 가장 높은 아이템 수)일 때,
아이템 1과 유사한 그룹 = 2(0.735), 3(0.912)
아이템 6과 유사한 그룹 = 4(0.829), 5(0.730)
3. 예측 (온라인)
온라인 : 사용자의 실시간 상호작용(클릭, 검색 등)을 반영하여 즉시 추천을 생성하는 방식
오프라인 : 추천 결과를 미리 계산해서 저장해놓는 방식.

- 가중치는 위에서 계산한 top k(=2)의 코사인 유사도임.
- 기존 평점 활용이라 범위를 벗어나지 않고 정수로 결과 반환.
2. 복잡도
온라인 단계
- 비어있는 아이템 평점에 예측 공식 활용해 예측 점수 계산
오프라인 단계
- 사용자-사용자(아이템-아이템) 유사도, 피어그룹 계산
- 계산한 유사도 미리 저장
- 주된 복잡성은 오프라인 단계에 있음.
[가정]
- 유저가 평점 매긴 최대 아이템 수는 n' << n
- n 개의 많은 아이템 중 최대 n'이라는 아이템에만 평점을 매김 (턱없이 부족하겠죠?)
- 아이템에 평점을 매긴 최대 유저 수는 m' << m
- m 명의 많은 사용자 중 오직 m'명만 평점을 매김 (이또한 부족할 것)
1. 시간 복잡도 (계산 수행 횟수)
[사용자 기반]
- 사용자 한 명에 대한 피어그룹 계산 O(mn')
- m: 사용자 한명한명, n': 평점 매긴 아이템 수
- 이걸 다른 사용자 명과 비교해야 함.
- 전체 사용자 수(m) 만큼 반복 O(m^2⋅n′)
- m^2는 정말 큰 수.. 이용자(m)가 많으니.
- 시간복잡도 매우 큼
[아이템 기반]
- O(n^2 m')
- n: 아이템 하나하나, m': 평점 매긴 사람 수
- 아이템 수(n)만큼 반복
- 아이템은 상대적으로 적기 때문에 시간 복잡도가 낮음.
2. 공간 복잡도 (메모리)
- 사용자 기반 = O(m^2)
- 아이템 기반 = O(n^2)
주로 n < m이기 때문에, 시간/공간 복잡도 모두에서 아이템 기반이 유리.
'추천시스템' 카테고리의 다른 글
| [추천시스템] week2 - 사용자 기반 이웃 모델 (변형) (0) | 2025.04.13 |
|---|---|
| [추천시스템] week2 - 사용자 기반 이웃 모델 (평점 예측 과정) (2) | 2025.04.13 |